Time-to-event analysis
Time-to-event (TTE) analysis, also known as survival analysis, is a set of statistical methods focusing on the time until an event occurs. A key feature of TTE data is that not all subjects need to experience the event by the end of the observation period, resulting in censored data, which these methods are designed to handle.
Events are outcomes that happen at a specific point in time.
When the same event can occur multiple times for the same subject, these repeated occurrences are known as recurrent events, and analyzing them is called repeated time-to-event (RTTE) analysis.
In some scenarios, multiple types of events can occur and must be considered simultaneously. For example, when evaluating death from different causes, each cause represents a mutually exclusive event that can only happen once, leading to competing risks. Competing risk analysis extends standard TTE methods to account for these mutually exclusive events.
An even further extension is multi-state analysis, which can accommodate both competing and non-competing events and model transitions between various states over time.
Theory
Hazard is a rate, not a probability.
The survivor function and the hazard function which are in essence opposed concepts. The survivor function focuses on surviving whereas the hazard function focuses on failing, given survival up to a certain time point.
Hazard
Understanding what the hazard means is at the heart of TTE analysis. The biological basis for events may be expressed quantitatively in terms of a hazard function. The hazard function models baseline survival. Like an elimination rate constant, ke, the hazard is simply a proportionality constant connecting amount to elimination.
\[ h(t)=\frac{f(t)}{S(t)}=-\frac{d}{d t} \ln S(t)=-\frac{S^{\prime}(t)}{S(t)} \tag{1}\]
The hazard has exactly the same meaning as ke—the proportionality constant relating people who are alive to the death rate. Hazards, exactly like elimination rate constants, have units of 1/time. Thus, the hazard is a rate, not a probability. Despite the name, the elimination rate constant may not be constant, and the same goes for hazards.
Survival
The survivor function (Equation 3) is calculated from the integral of the hazard with respect to time—a quantity called the cumulative hazard (Equation 2). The cumulative hazard is sometimes known as the “risk”.
\[ H(t)=\int_0^t h(u) d u=-\log (S(t)) \tag{2}\]
\[ S(t) = P(T > t) = \int_{t}^\infty f(u)\,du = e^{-H(t)} \tag{3}\]
Cumulative distribution
The probability of individual having an event before, or at, time t.
\[ F(t) = P(T \le t) = 1 - S(t) \tag{4}\]
Probability density
The likelihood of observing an event at a particular time is predicted by the probability density function (PDF). When the exact time of the event is observed, the likelihood is the product of the survivor function and the hazard at that time (Equation 5).
\[ f(t) = S(t) \times h(t) = -\frac{d S(t)}{dt}=\frac{d}{dt} F(t) \tag{5}\]
When the hazard is constant, the shape of the PDF is exponential.
In real life, the time of zero is at entry into a clinical study, and it is unrealistic to imagine that at exactly that instant, the hazard of an event such as death plunges to zero.
Models
The Cox model is the most widely used survival model in the health sciences, but it is not the only model available. A key reason why the Cox model is widely popular is that it does not rely on distributional assumptions for the outcome. Also, an estimation of the baseline hazard is not necessary for the estimation of a hazard ratio because the baseline hazard cancels in the calculation.
In pharmacometrics we often use parametric survival models. A parametric survival model is one in which the survival time (the outcome) is assumed to follow a known distribution, and the parameters of this distribution is modelled.
Survival estimates obtained from parametric survival models typically yield plots more consistent with a theoretical survival curve. If the investigator is comfortable with the underlying distributional assumption, then parameters can be estimated that completely specify the survival and hazard functions. This simplicity and completeness are the main appeals of using a parametric approach.
The hazard function is not specified in a Cox model. However, it is not assumed constant.
Distributions commonly used for parametric survival models in pharmacometrics are:
| Distribution | h0(t) | PH | AFT | |
|---|---|---|---|---|
| Exponential | \(\sigma\) | \(\sigma = e^{\beta_0}\) | \(\sigma = e^{-\alpha_0}\) | |
| Gompertz | \(\sigma e^{\lambda t}, 0 \le t, \sigma > 0\) | ✅ | ❌ | |
| Weibull1 | \(\rho \lambda (\rho t)^{\lambda - 1}\) | ✅ | ✅ | |
| Log-normal2 | \(\frac{(t \sigma \sqrt{2 \pi})^{-1} e^{-(\frac{Z^2}{2})}}{1 - \Phi(Z)}, Z = \frac{\ln{t} - \mu}{\sigma}\) | ❌ | ✅ | |
| Log-logistic | \(\frac{\rho \lambda(\rho t)^{\lambda - 1}}{1 + (\rho t)^\lambda}, 0 \le t, \lambda > 0\) | ❌ | ✅ | |
| Generalized log-logistic3 [2] | \(\frac{\rho_1 \lambda (\rho_1 t)^{\lambda - 1}}{1 + (\rho_2 t)^\lambda}, (t; \rho_1; \rho_2; \lambda) > 0\) | ✅ | ❌ |
The survivor function S(t) can be calculated numerically, see Equation 3.
- \(\sigma\) is sometimes called the “scale” parameter. It stretches/shrinks a distribution (c.f. standard devation in a normal distribution). Typically, it is reparameterized in terms of covariates COVn and regression parameters \(\beta_n\): \(\sigma = e^{\beta_0 + \sum \beta_n \mathrm{COV}_n}\).
- \(\lambda\) is sometimes called the “shape” (or “form”) parameter; for Weibull it is also sometimes called “slope”.
- \(\rho = \frac{1}{\sigma}\) is sometimes called the “rate” (or “inverse scale”) parameter.
- A “location” parameter \(\mu\) is sometimes seen. This shifts the distribution along the t-axis as \(t - \mu\) (c.f. mean in a normal distribution). In pharmacometrics this is usually not needed, since the distribution should always start at the start of the study, \(t_\text{start} \equiv 0\). Thus, \(\mu = 0\), and is not displayed.
The Weibull distribution has several parameterizations. The one displayed in Table 1 is the most common in pharmacometrics due to favorable numerical properties.
The survival package in R uses the same parameterization. Interestingly, base-R uses the “standard” parameterization with scale parameters instead of rates.
- Weibull reduces to the exponential if \(\lambda = 1\).
- Weibull and lognormal are special cases of the generalized lambda.
- The lognormal model can only be expressed in terms of integrals.
- The shape of the lognormal distribution is very similar to the log-logistic distribution and yields similar model results.
NONMEM code: Exponential distribution
$SUBROUTINES ADVAN=13
$MODEL COMP=(HAZARD) ; Comartment for integration of hazard
$PK
SCALE = EXP(THETA(1)) * EXP(ETA(1)) ; constant hazard
$DES
DADT(1) = SCALE ; Integration of hazard
$ERROR
IF (NEWIND < 2) OLDCHZ = 0
CHZ = A(1) - OLDCHZ
OLDCHZ = A(1) ; For each ID, cum hazard from previous obs. to new obs.
SUR = EXP(-CHZ) ; Survival function
HAZNOW = SCALE
IF (DV == 0) Y = SUR ; Censored event
IF (DV == 1) Y = SUR * HAZNOW ; Event
$THETA (-Inf, 1, Inf) ; Scale
$OMEGA 0 FIX ; placeholder
$ESTIMATION METHOD=0 LIKELIHOODNONMEM code: Weibull distribution
$SUBROUTINES ADVAN=13
$MODEL COMP=(HAZARD) ; Comartment for integration of hazard
$PK
; For RTTE, time of previous event
; For TTE TP is always 0
IF (NEWIND < 2) TP = 0
RATE = EXP(THETA(1)) * EXP(ETA(1))
SHAPE = EXP(THETA(2))
$DES
DEL = 1E-6
TX = T + DEL
DADT(1) = RATE * SHAPE * (RATE * (TX - TP))**(SHAPE - 1) ; Integration of hazard
$ERROR
IF (NEWIND < 2) OLDCHZ = 0
CHZ = A(1) - OLDCHZ
OLDCHZ = A(1) ; For each ID, cum hazard from previous obs. to new obs.
SUR = EXP(-CHZ) ; Survival function
HAZNOW = RATE * SHAPE * (RATE * (TIME - TP) + DEL)**(SHAPE - 1)
IF (DV == 0) Y = SUR ; Censored event
IF (DV == 1) Y = SUR * HAZNOW ; Event
$THETA (-Inf, 1, Inf) ; Rate
$THETA (-Inf, 2, Inf) ; Location
$OMEGA 0 FIX ; placeholder
$ESTIMATION METHOD=0 LIKELIHOODNONMEM code: Lognormal distribution
$SUBROUTINES ADVAN=13
$MODEL COMP=(HAZARD) ; Comartment for integration of hazard
$PK
SCALE = EXP(THETA(1)) * EXP(ETA(1)) ; Sigma/Standard deviation
LOCATION = EXP(THETA(2)) ; Mu/Mean
$DES
DEL = 1E-6 ; to avoid log(0)
TX = T + DEL
Z = (LOG(TX) - LOCATION) / SCALE
; Integration of hazard.
DADT(1) = (EXP(-(0.5 * Z**2)) / (SCALE * TX * SQRT(2 * PI))) / &
(1 - PHI(Z)) ; PHI() is a builtin NONMEM function
$ERROR
IF (NEWIND < 2) OLDCHZ = 0
CHZ = A(1) - OLDCHZ
OLDCHZ = A(1) ; For each ID, cum hazard from previous obs. to new obs.
SUR = EXP(-CHZ) ; Survival function
DELX = 1E-6 ; to avoid log(0)
TIMX = TIME + X
ZX = (LOG(TIMX) - LOCATION) / SCALE
HAZNOW = (EXP(-(0.5 * ZX**2)) / (SCALE * TIMX * SQRT(2 * PI))) / &
(1 - PHI(ZX))
IF (DV == 0) Y = SUR ; Censored event
IF (DV == 1) Y = SUR * HAZNOW ; Event
$THETA (-Inf, 1, Inf) ; Scale
$THETA (-Inf, 2, Inf) ; Location
$OMEGA 0 FIX ; placeholder
$ESTIMATION METHOD=0 LIKELIHOODNONMEM code: (Generalized) log-logistic distribution
$SUBROUTINES ADVAN=13
$MODEL COMP=(HAZARD) ; Comartment for integration of hazard
$PK
RATE_1 = THETA(1) * EXP(ETA(1))
RATE_2 = THETA(2) ; If equal to RATE_1, then reduces to log-logistic
SHAPE = THETA(3)
$DES
DEL = 1E-6 ; to avoid log(0)
TX = T + DEL
DADT(1) = (RATE_1 * SHAPE * ((RATE_1 * TIMX)**(SHAPE - 1))) / &
(1 + (RATE_2 * TIMX)**SHAPE)
$ERROR
IF (NEWIND < 2) OLDCHZ = 0
CHZ = A(1) - OLDCHZ
OLDCHZ = A(1) ; For each ID, cum hazard from previous obs. to new obs.
SUR = EXP(-CHZ) ; Survival function
DELX = 1E-6 ; to avoid log(0)
TIMX = TIME + X
HAZNOW = (RATE_1 * SHAPE * ((RATE_1 * TIMX)**(SHAPE - 1))) / &
(1 + (RATE_2 * TIMX)**SHAPE)
IF (DV == 0) Y = SUR ; Censored event
IF (DV == 1) Y = SUR * HAZNOW ; Event
$THETA (-Inf, 1, Inf) ; Rate 1
$THETA (-Inf, -2, Inf) ; Rate 2, unique to the generalized form of log-logistic
$THETA (-Inf, -1, Inf) ; Shape
$OMEGA 0 FIX ; placeholder
$ESTIMATION METHOD=0 LIKELIHOODNONMEM code: TTE simulation for VPC
$SUBROUTINES ADVAN=13
$MODEL COMP=(HAZARD) ; Comartment for integration of hazard
...
$ERROR
...
IF (DV == 0) Y = SUR ; Censored event
IF (DV == 1) Y = SUR * HAZNOW ; Event
EOS = 28 ; End of Study, TIME
;------------For Simulation----------------
IF (ICALL == 4) THEN
IF (NEWIND < 2) THEN
CALL RANDOM (2,R)
ENDIF
DV = 0
TTE = 0
IF (TIME == EOS) TTE = 1 ; right-censor
IF (R > SUR) THEN
DV = 1
TTE = 1
ENDIF
ENDIF
...
$SIMULATION (7840) (1305 UNIFORM) ONLYSIMULATION NOPREDICTIONThe power of the hazard function becomes evident in pharmacometric applications when factors changing the hazard vary with time. An example would be if drug treatment influenced the hazard. The effects of the drug will depend on concentration and thus, the hazard in the drug-treated arm will vary with the time course of drug concentration.
When there are no time-varying covariates involved, there is often an analytical solution to obtain the cumulative hazard, and from that, it is easy to predict the survivor function and the PDF. For more flexible hazard functions involving time-varying covariates, analytical solutions are not usually available. With software like NONMEM that is able to numerically integrate the hazard function, there is no restriction on the way the hazard is expressed4.
The Weibull model also has another key property: the log(–log) of S(t) is linear with the log of time. This allows a graphical evaluation of the appropriateness of a Weibull model by plotting the log negative log of the Kaplan–Meier survival estimates against the log of time.
To see this linear relationship: start with the Weibull survival function \(S(t) = e^{-\sigma t^p}\), take the log of \(S(t)\), multiply by negative one, and take the log again. For the Weibull distribution, the \(\ln{-\ln{S(t)}}\) is a linear function of \(\ln{t}\) with slope p and intercept \(p \ln{\sigma}\). If the slope equals one then t follows an exponential distribution.
Possible results:
- Parallel straight lines: Weibull, PH, and AFT assumptions hold
- Parallel straight lines with slope of 1: Exponential. PH and AFT
- Parallel but not straight lines: PH but not Weibull, not AFT (can use Cox model)
- Not parallel and not straight: Not Weibull, PH violated
- Not parallel but straight lines: Weibull holds, but PH and AFT violated, different p
The key points are that straight lines support the Weibull assumption and parallel curves support the PH assumption.
The log-logistic assumption can be graphically evaluated by plotting \(\ln{\frac{1-S(t)}{S(t)}}\) against \(\ln{t}\) where \(S(t)\) are the Kaplan–Meier survival estimates. If survival time follows a loglogistic distribution, then the resulting plots should be a straight line of slope \(p\).
Possible results:
- Straight lines: log-logistic assumption holds
- Parallel curves: PO assumption holds
- Parallel straight lines: log-logistic, PO, and AFT assumptions hold
Proportional hazard (PH)
The underlying assumption for PH models is that the effect of covariates is multiplicative (proportional) with respect to the hazard.
The PH assumption is applicable for a comparison of hazards.
Non-proportional hazard (NPH)
Several scenarios can lead to NPH. For example:
- Delayed treatment effect
- Diminishing treatment effect
- Crossing hazards
Proportional odds (PO)
A PO survival model is a model in which the survival odds ratio is assumed to remain constant over time. This is analogous to a PH model where the hazard ratio (HR) is assumed constant over time.
Accelerated failure time (AFT)
The underlying assumption for AFT models is that the effect of covariates is multiplicative (proportional) with respect to survival time. It either stretches or contracts survival time
The AFT assumption is applicable for a comparison of survival times. Many parametric models are acceleration failure time (AFT) models in which survival time is modeled as a function of predictor variables.
The acceleration factor is the key measure of association obtained in an AFT model. It allows the investigator to evaluate the effect of predictor variables on survival time just as the hazard ratio allows the evaluation of predictor variables on the hazard. The acceleration factor is a ratio of survival times corresponding to any fixed value of S(t). For AFT models, this ratio of survival times is assumed constant for all fixed values of S(t). Although the hazard ratio is a more familiar measure of association for health scientists, the acceleration factor has an intuitive appeal, particularly for describing the efficacy of a treatment on survival.
An acceleration factor greater than one for the effect of an exposure implies that being exposed is beneficial to survival whereas a hazard ratio greater than one implies being exposed is harmful to survival (and vice versa).
Adding covariates
There are four approaches to modelling survival data with covariates5:
- Parametric Families
- Accelerated Life
- Proportional Hazards
- Proportional Odds
Typically in pharmacometrics, we use the Proportional Hazards approach (Equation 6). In this approach, we assume that the effect of the covariates is to increase or decrease the hazard by a proportionate amount at all durations.
The standard lognormal and log-logistic distributions are not closed under proportional hazards. That is, if you try to impose a proportional hazards (PH) assumption of covariate effects on a lognormal baseline function, the resulting distribution need not be lognormal.
https://stats.stackexchange.com/questions/600557/how-to-parameterize-covariates-in-parametric-time-to-event-model-lognormal-dist
\[ h(t, \text{COV}) = h_0(t) \times e^{\sum \beta_n \text{COV}_n} \tag{6}\]
Where h0(t) is the baseline hazard function (see Table 1).
Frailty
Frailty accounts for unobserved heterogeneity. This can be modelled using a ETA in NONMEM, using the same approach as adding a covariate. This can be viewed as adding all possible covariates, even unobserved ones.
Landmark analysis
Landmark analysis is used to correct for immortal time bias [3]. This bias is inherent in the analysis of time-to-event outcome between groups determined during study follow-up [4]. This method was originally proposed to evaluate the association between treatment response and survival6, or to allow for groupings based on any covariate whose value is not known at baseline.
Looking at Figure 1, an incorrect approach would be to classify Subject 1 as a non-responder and Subjects 2 and 3 as responders (as is the case at six months) and then compare the survival between these two groups.
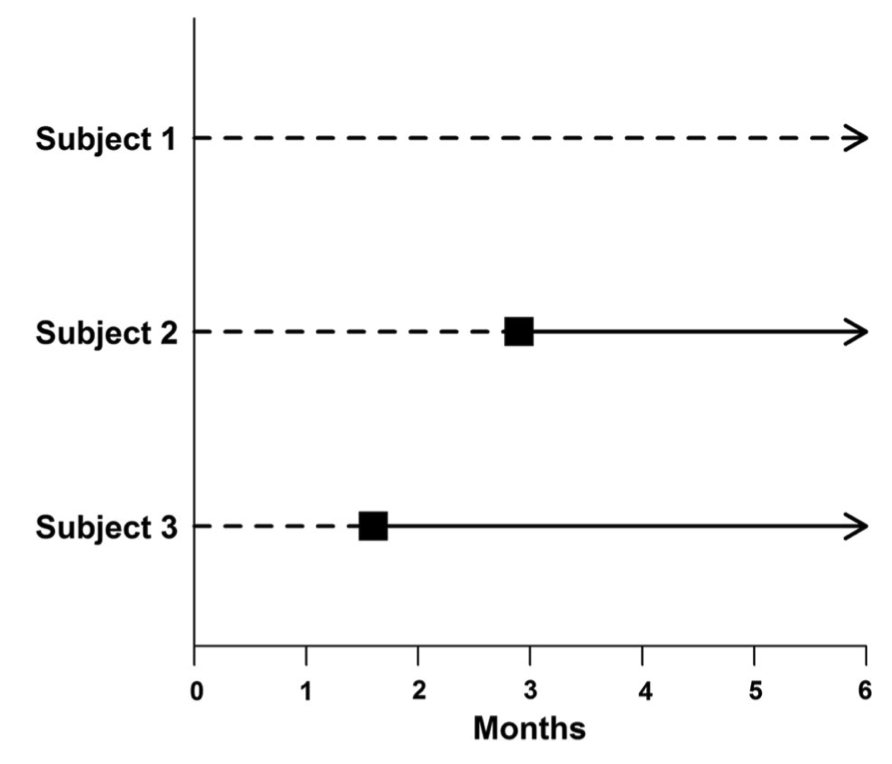
That is, “responders” and “nonresponders” are compared with regard to survival from the start of the study. This assumes that Subjects 2 and 3 responded to treatment immediately. However, response status (group assignment) is unknown at baseline. That is, all subjects begin the study as non-responders and do not become responders until later. Responders are (by definition) guaranteed to survive at least until the time of response. Classifying groups in this way leads to immortal time bias.
How to perform landmark analysis
The landmark method analyzes survival based on patient response at a fixed time after starting therapy, called the “landmark”. Any subjects who were lost to follow-up or died prior to this time point are excluded from further analysis. Subjects are then grouped by their response status at the landmark. Any subject who has not responded by the landmark time is classified as a non-responder, even if that subject later responds to treatment. This approach estimates survival from the landmark, based on response status at that time.
It is commonly used in clinical trials to classify patients into groups based on events during follow-up, such as receiving a treatment, stopping medication, or switching treatment.
Two examples of this process:
- In Figure 2, a landmark time of two months post-treatment is chosen. Subjects 1 and 2 are then classified as non-responders because neither subject has responded to treatment at that time. Note that even though Subject 2 will later go on to respond to treatment, to avoid the immortal time bias, Subject 2 must be considered to be a non-responder due to his or her status at the landmark time. Subject 3 responded to treatment prior to the landmark time and is thus classified as a responder.
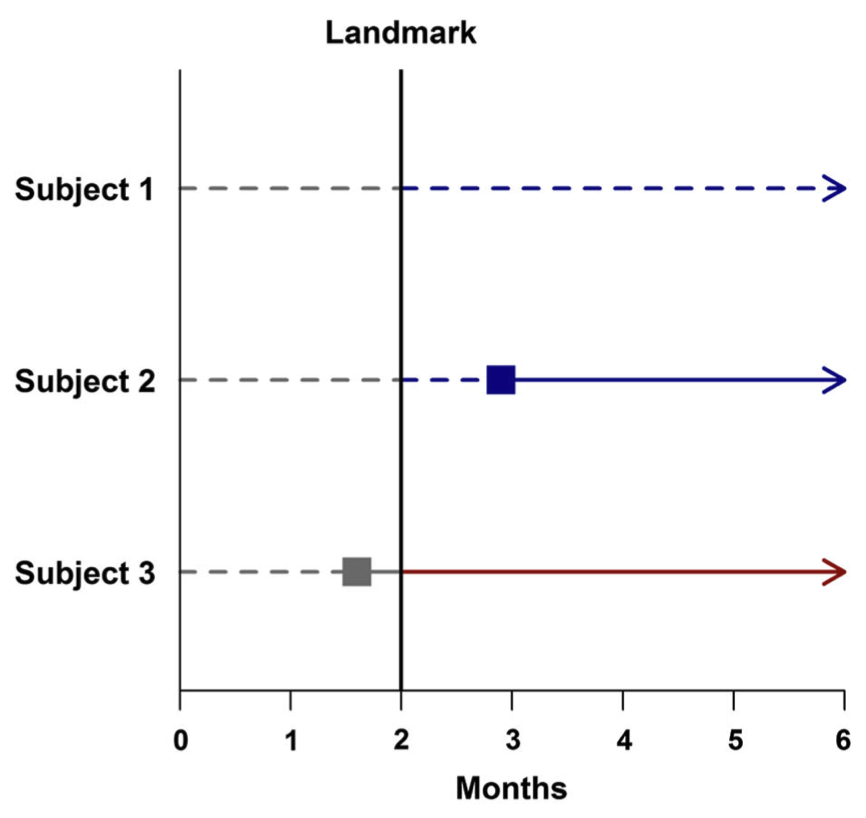
- As can be seen in Figure 3, selecting a different landmark time (here, four months post-treatment) may change the classification of some subjects. In this example, the later landmark allows Subject 2 enough time to respond to treatment, leading to this subject being placed in the responder group.
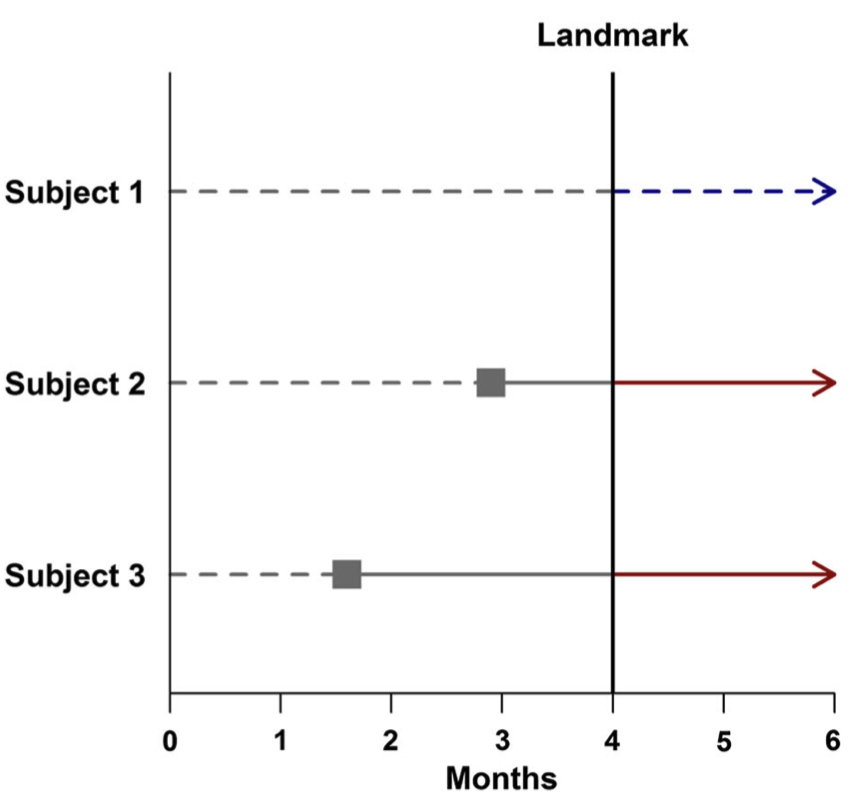
Once the landmark has been chosen, any ineligible subjects have been excluded, and subjects have been classified according to their status at the landmark time, the usual survival analysis methods are applied. The results of these methods are interpreted as usual, with the important caveat that conclusions are only generalizable to subjects who have survived until the landmark time.
To avoid bias, the landmark should be chosen before data analysis begins and ideally should correspond to a clinically meaningful period of time. When the choice of landmark time is not obvious, the data should be analyzed using multiple landmark times in order to determine the sensitivity of the findings to the choice of landmark.
An alternative to landmark analysis is to allow the value of the covariate indicating treatment response to vary over time. This is doable using pharmacometric software such as NONMEM. This does not require any subjects or events to be excluded from the analysis. Is also avoids both the problem of selecting a landmark time and any misclassification errors.
References
Footnotes
Pronounced “Veibull”, with “v” as in “very”↩︎
The shape of the lognormal distribution is very similar to the log-logistic distribution and yields similar model results. [1]↩︎
If \(\rho_1 = \rho_2\) then this reduces to the log-logistic.↩︎
Except the user needs to ensure that the hazard does not go negative.↩︎
Anderson JR, Cain KC, Gelber RD. Analysis of survival by tumor response. J Clin Oncol. 1983;1:710–719.↩︎